搜索引擎的核心在于根据**关键词(term)找到相关文档(document)**的能力。为了实现这一目的,lucene针对每个term维护了一个倒排链(posting list),即包含该term的docId列表。
什么是倒排索引
正排索引
即docId - document的键值对
| docId | name | age |
|---|---|---|
| 1 | Jack | 20 |
| 2 | Bob | 22 |
| 3 | Jack | 20 |
| 4 | Alice | 20 |
| 5 | Jack | 19 |
| 6 | Bob | 19 |
类似于mysql索引,根据docId可以查询到相应的文档信息。
倒排索引
倒排索引是关键词(term)到文档id列表的映射关系。例如针对上面这张表格,可以建立两个倒排索引,分别是name和age Index。
name index
| term dictionary | posting list |
|---|---|
| Jack | [1,3,5] |
| Bob | [2,6] |
| Alice | [4] |
age index
| term dictionary | posting list |
|---|---|
| 19 | [5,6] |
| 20 | [1,3,4] |
| 22 | [2] |
这样,针对每一个关键词term,都可以查询出对应的docId列表。
对term dictionary进行排序后,得到一个有序的term列表,可以通过二分法进行查询,这样的时间复杂度是O(logN),空间复杂度是O(N*len(key)),和term数量成正比。当term数量极为庞大,内存里也放不下时,需要对term进行索引来提高效率。
Term Index
Trie树
假设字符的种数有m个,有若干个长度为n的字符串构成了一个Trie树,则每个节点的出度为m(即每个节点的可能子节点数量为m),Trie树的高度为n。很明显我们浪费了大量的空间来存储字符,此时Trie树的最坏空间复杂度为O(m^n)。也正由于每个节点的出度为m,所以我们能够沿着树的一个个分支高效的向下逐个字符的查询,而不是遍历所有的字符串来查询,此时Trie树的最坏时间复杂度为O(n)。这正是空间换时间的体现,也是利用公共前缀降低查询时间开销的体现。
相较于hash表,trie树支持动态查询,可以进行前缀,后缀,范围查询,在搜索场景下明显优于hash表。
FSA
FSA是一个FSM(有限状态机)的一种,特性如下:
* 确定:意味着指定任何一个状态,只可能最多有一个转移可以访问到。
* 无环: 不可能重复遍历同一个状态
* 接收机:有限状态机只“接受”特定的输入序列,并终止于final状态。
事实上字典树也是一种FSA,但TRIE树只共享前缀,而FSA不仅共享前缀还共享后缀。假设我们用星期一、二、四去掉共同的day后缀组成一个Set: mon,tues,thurs。相应的TRIE是这样的,只共享了前缀。

TRIE有重复的3个final state:3、8、11。 而8、11都是s转移,是可以合并的,FSA共享后缀后:

进一步降低了存储空间。
FST
FST类似于FSA,区别在于给定一个key除了能回答是否存在,还能输出一个关联的值。
依然以mon,tues,thurs这个集合为例,以星期天为一周的第1天,我们的mon对应2,tues对应3,thurs对应5,那么最后生成的FST就如下图所示,/后表示要输出的值:
-
路径m->o->n将会输出2
-
路径t->u->e->s将会输出3
-
路径t->h->u->r->s将会输出5
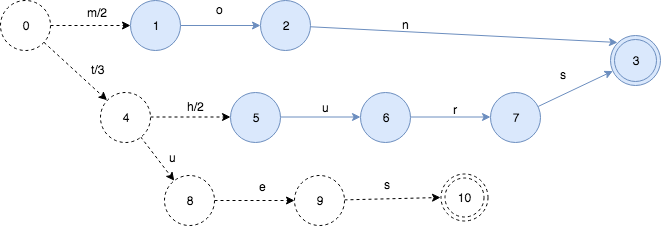
当然,满足上诉输出条件并不只有这一种FST,比如可以m -> o -> n的路径上的m/2改成o/1\`n/1`.
关键点在于:每一个key,都在FST中对应一个唯一的路径。因此,对于任何一个特定的key,总会有一些value的组合使得路径是唯一的,我们需要做的就是如何来在转移中分配这些组合。如何构建FST留待下周。
通过FST构建term index,可以大大降低需要的存储空间,使term index可以被缓存到内存中,查询时只需要在匹配到term时进行一次磁盘访问,降低了磁盘操作时间。
联合索引查询
例如对上表进行 name == ‘xx’ and age == ‘yy’ 的查询,在mysql数据库中需要对age和name分别建立索引,查询结果后进行合并,或者建立联合索引。
而对于lucene来说,实际上是根据term找到相应的倒排链,再对两条倒排链进行合并。倒排链的数据结构有两种解决方案,分别是skiplist(跳表)和bitset
Skip List
SkipList有以下几个特征:
-
元素排序的,对应到我们的倒排链,lucene是按照docid进行排序,从小到大。
-
跳跃有一个固定的间隔,这个是需要建立SkipList的时候指定好,例如下图以间隔是3
-
SkipList的层次,这个是指整个SkipList有几层
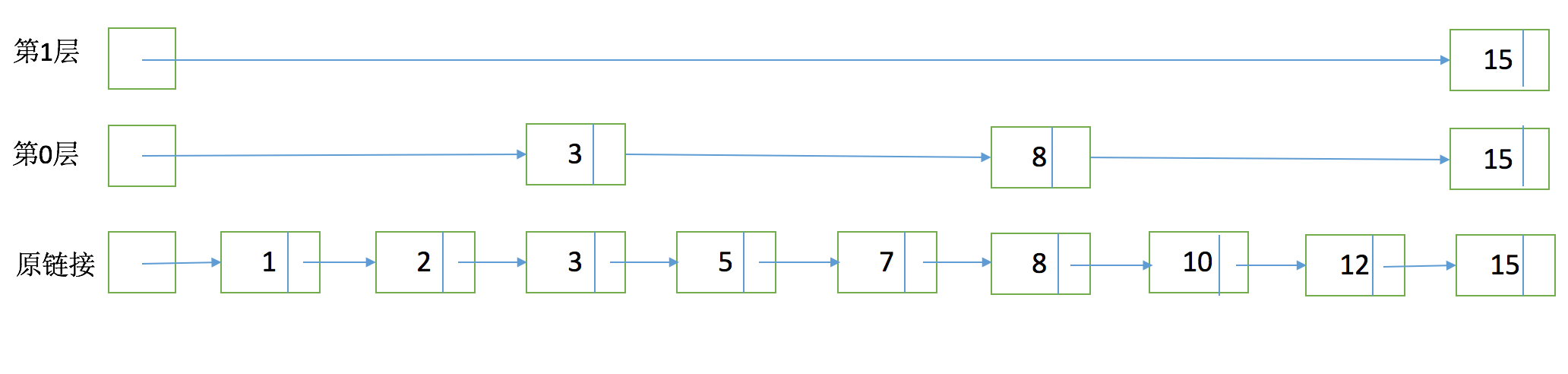
有了这个SkipList以后比如我们要查找docid=12,原来可能需要一个个扫原始链表,1,2,3,5,7,8,10,12。有了SkipList以后先访问第一层看到是然后大于12,进入第0层走到3,8,发现15大于12,然后进入原链表的8继续向下经过10和12。
SkipList本质上是在有序的链表上实现实现二分查找,它能有效的提升链表的查找效率,其时间复杂度为O(logn)(其中n为链表长度)。简单说SkipList优化了Postings的随机查找的性能问题。
假如我们有下面三个倒排链需要进行合并。

在lucene中会采用下列顺序进行合并:
-
在termA开始遍历,得到第一个元素docId=1
-
Set currentDocId=1
-
在termB中 search(currentDocId) = 1 (返回大于等于currentDocId的一个doc),
-
因为currentDocId ==1,继续
-
如果currentDocId 和返回的不相等,执行2,然后继续
-
-
到termC后依然符合,返回结果
-
currentDocId = termC的nextItem
-
然后继续步骤3 依次循环。直到某个倒排链到末尾。
整个合并步骤我可以发现,如果某个链很短,会大幅减少比对次数,并且由于SkipList结构的存在,在某个倒排中定位某个docid的速度会比较快不需要一个个遍历。可以很快的返回最终的结果。从倒排的定位,查询,合并整个流程组成了lucene的查询过程,和传统数据库的索引相比,lucene合并过程中的优化减少了读取数据的IO,倒排合并的灵活性也解决了传统索引较难支持多条件查询的问题。
bitset
bitset 是一种很直观的数据结构,对应 posting list 如:[1,3,4,7,10]
对应的 bitset 就是: [1,0,1,1,0,0,1,0,0,1] ,每个文档按照文档 id 排序对应其中的一个 bit。Bitset 自身就有压缩的特点,其用一个 byte 就可以代表 8 个文档。所以 100 万个文档只需要 12.5 万个 byte。但是考虑到文档可能有数十亿之多,在内存里保存 bitset 仍然是很奢侈的事情。而且对于个每一个 filter 都要消耗一个 bitset,比如 age=18 缓存起来的话是一个 bitset,18<=age<25 是另外一个 filter 缓存起来也要一个 bitset。 Lucene 会对bitset再进行压缩,称之为 Roaring Bitmap。压缩的思路其实很简单。与其保存 100 个 0,占用 100 个 bit。还不如保存 0 一次,然后声明这个 0 重复了 100 遍。
这两种合并使用索引的方式都有其用途。Elasticsearch 对其性能有详细的对比。简单来说对于简单的相等条件的过滤缓存成纯内存的 bitset 还不如需要访问磁盘的 skip list 的方式要快。